Aggregates & Entities in Domain-Driven Design
Here are some thoughts on distinctions between aggregates and entities in domain-driven design (DDD), in response to some good questions Harry Brumleve asked me via email.
Here is the relevant content from the email:
I've always had problems with Aggregates vs. Entities. Is it that Agg's are transactional boundaries that expose behaviors (methods) that the entities they contain may perform? Entity is a business concept that exposes behavior. A collection of entities may have different behavior varied upon the type of aggregate that encapsulates it? Or is it that Agg Root = Entity and it's an arbitrary naming of the same concept? Or is this over-thinking it?
Let’s use the typical example of a purchase order (PO) and its line items. How you might model this as entities and value objects? And is there an aggregate concept lurking in there?
A Concrete Example
I’ve done this in the past as Purchase Order being an entity, since it has identity and a lifecycle. The lifecycle could be modeled as object state or as an event stream - it doesn’t matter for our purposes here. The line items would likely be value objects, since its their properties that probably matter more than trying to preserve identity over time for them. There may need to be other objects associated with the PO, but let’s keep it simple.
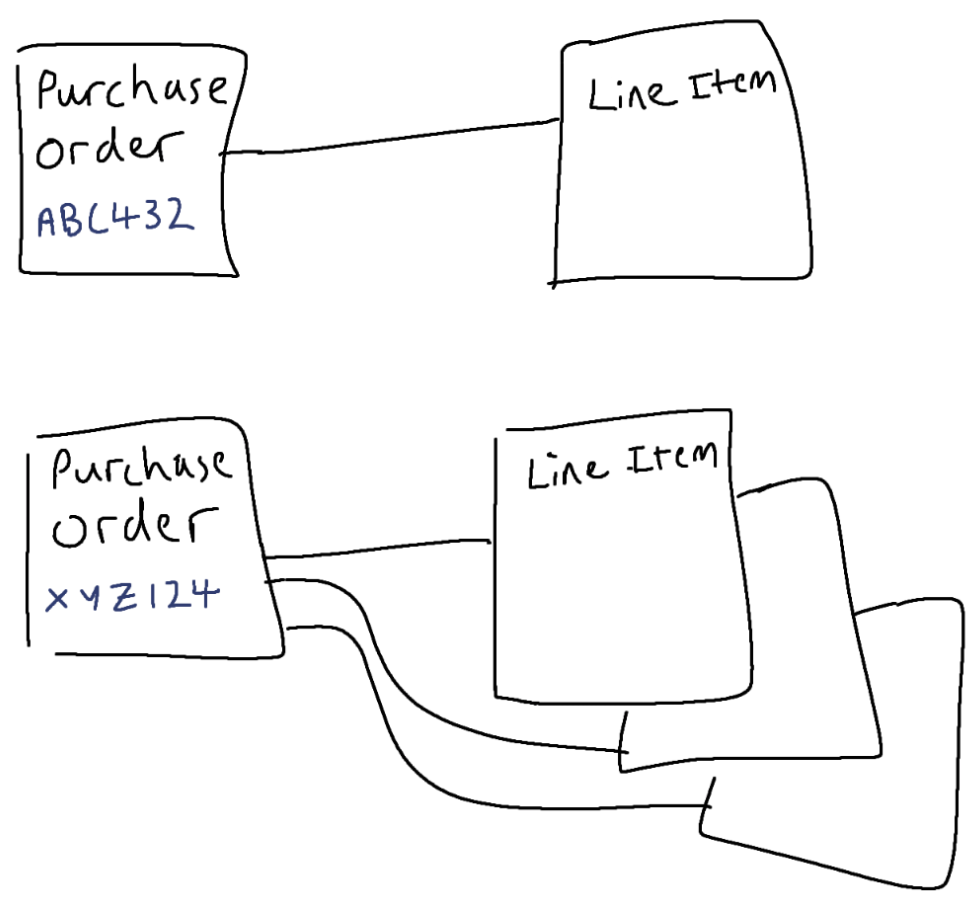
Let’s say your company needs to create a purchase order for an 4 day agile workshop class, because creating purchase orders for training is how they roll. Using the model I described, you would have a single Purchase Order and one Line Item for the class. Unlike the agile classes I teach, which are one inclusive price, other companies offering training and coaching might want to break out the costs to rent a venue, pay for catering, cover instructor travel expenses, coaching days etc. So purchase orders would need to handle multiple line items in many cases. This is fairly standard for POs anyway.
Aggregates Support Higher Level Concepts
The business could work with LineItems individually, but in practice never would, since they only really make sense in light of their PurchaseOrder. And you would mostly likely want to work with the higher-level concept of Purchase Orders rather than always having to deal at the granularity of the Line Items.
If someone was to approve Purchase Order with ID=XYZ124, they would typically be approving all its Line Items as well. I could imagine business rules for certain types of Purchase Orders that the sum of the values of the individual Line Items could not exceed a certain amount for the Purchase Order to be approved. A Purchase Order would probably need to have at least one Line Item to be valid.
Here is a case of two or more objects that seem to belong together most of the time in terms of how you need to work with them. So treat PO as an aggregate of the PO entiity and the Line Item value objects. And make the PO entity the root of the aggregate. So what we have in this example is an aggregate consisting of a single entity, the Purchase Order (functioning as the root of the aggregate), and a set of one or more associated Line Item value objects.
Aggregates, Invariants and Consistency
This aggregate boundary is part of the model, and allows us to enforce invariants (e.g. having at least one Line Item) for the PO aggregate. Between POs we can have eventual consistency, since we are comfortable with not trying to keep all our aggregates in sync with each other. We can update the PO with ID=XYZ124 and then update another related PO with ID=ABC432 separately.
In terms of how this plays out, you would typically have a repository for persisting and retrieving the PO aggregates. When you get a PO from its repository, it would be created whole, with all its Line Items as well. As an aside, this is what makes document stores a nice fit for aggregates, since aggregate and document boundaries often tend to align in terms of how a model is used.
I realize none of what I’ve written above is directly answering your questions, but it always helps me to try to have a concrete example to discuss. In a particular model, I’ve typically only had each entity be part of one aggregate. But that may be because I haven’t seen a domain yet where the model needed anything more complicated.
For background reading, see the DDD Reference book, especially pp. 18, 19 and 24.
Aggregate Boundaries and Behavior
I love concrete examples. This actually demonstrates my confusion between Aggregates and Root Entities. I obviously need to think this out _a lot more_, but I've always felt like the diagram you've sent has aggregates in the wrong spot. Namely, that aggregates represent a collection of behaviors that are transactionally bound and express the domain model.
I can see how you might define an aggregate this way, and I think it’s a valid way to conceptualize them.
The entities make up the design and implementation of an aggregate's behaviors; since they are encapsulated within aggregates,
I would rather have most of the behaviors tied to value objects rather than entities. One of the things I’d encourage is to keep entities free of behavior where possible, since identity is already a big burden to bear, and have behavior expressed in the value objects. So as more behavior needs to be added to this PO, I would try to model that as behaviors on new or existing value objects where possible.
How they contribute to the make up of the aggregate's composition is arbitrary and not important to the domain outside of the aggregate's context.
"Arbitrary and not important" might be a little too strong a statement for me. I’d need an example of where this would be the case. However, generally speaking, I think you’re correct.
Additionally, I feel that an Aggregate Root concept is a vestigial idea posited by Eric to appease some OO or implementation concern. :-) That may just be me being cheeky, though.
Possibly. I’ve not implemented a system using CQRS, which takes aggregates in a different and interesting direction from what Eric originally proposed. I find the aggregate root concept helpful though, since a single entity typically takes that responsibility.
Aggregate Boundaries and Refining the Model
To your point, if entities aren't used across aggregate types, aren't you really using the behaviors of the aggregates to express your model and the entities to express the arbitrary design of a particular aggregate?
Yes, if I understand you correctly.
As a concrete example, a PO has several behaviors that may not change as a training organization moves from inferiority to not-as-optimal. The design and implementation may currently consider entities like "Location Rental" or "Travel Expenses" to express the PO model; but after maturity of the model and company they choose to represent their line items more succinctly or with less inferior concepts. The entities will change, or yield to new entity concepts, but the PO aggregate’s boundary stays in tact.
Aggregate boundaries may, and likely will, change over time as the model matures. That’s assuming the team is practicing iterative design and growing their model as their understanding grows. Maybe the team realizes that Location Rental needs to be its own aggregate, for example. And if a PO is canceled then the Location Rental needs to be canceled too.
To your point, though, the entities, value objects and domain events inside the aggregate could potentially change without affecting the aggregate boundary.
Is the answer to my conundrum "it depends" & "do what's best for your organization"? :-)
Always! :) That being said, there’s clearly some nuance here and probably the need to sketch out some ideas on napkins to clarify each other’s thinking.
See the Cargo aggregate in the Ruby DDD sample app for a half-decent example. Cargo is the aggregate root, with several value objects handling the business rules. Delivery essentially functions as a read projection of the Handling Event history. Cargo is focused on identity and not much else. All the interesting business logic is in the value objects.
About the Author
 Paul is a software design and development coach and mentor. He is available for consulting and training through his company, Virtual Genius LLC. He is the author of The EventStorming Handbook and major contributor to Behavior-Driven Development with Cucumber. He is also the founder and chair for the Explore DDD conference.
Paul is a software design and development coach and mentor. He is available for consulting and training through his company, Virtual Genius LLC. He is the author of The EventStorming Handbook and major contributor to Behavior-Driven Development with Cucumber. He is also the founder and chair for the Explore DDD conference.